Learn business

릴레이션 키 총 정리
■ 릴레이션 키 총 정리• 릴레이션의 키는 각 투플을 고유하게 식별할 수 있는 하나 이상의 애트리뷰트들의 모임이다.• 일반적으로 키는 두 릴레이션을 서로 연관시키는 데 사용된다.(RDB의 특징이다. 계층, 네트워크 데이터베이스는 레코드들로 서로 관계를 나타냄)• 릴레이션의 투플을 접근하는 속도를 높이기 위해 키에 인덱스를 만드는데, 키가 작을수록 인덱스의 크기가 줄어들고 인덱스를 검사하는 시간이 단축된다. 1. 수퍼 키• 수퍼 키는 한 릴레이션 내의 특정 투플을 고유하게 식별하는 하나의 애트리뷰트 또는 애트리뷰트들의 집합이다. • 신용카드 회사의 고객 릴레이션에서 (신용카드번호, 주소) 또는 (주민등록번호, 이름) 또는 (주민등록번호)는 모두 수퍼 키가 될 수 있다. • 또는 신용카드번호나 주민등록번호를..
ANSI/SPARC 3단계
■ANSI/SPARC 3단계※ DBMS의 주요 목적은 사용자에게 데이터에 대한 추상적인 뷰를 제공하는 것이다. 즉, 데이터가 어떻게 저장되고 유지되는가에 관한 상세한 사항을 숨기고 있는 것이다. 현재 상용 DBMS 구현에서 사용되는 일반적인 아키텍처는 ANSI/SPARC 아키텍처이다.※ ANSI/SPARC 아키텍처의 주요 목적은 데이터 독립성을 제공하는 것이다. 데이터의 독립성은 논리적 데이터 독립성과 물리적 데이터 독립성으로 구분할 수 있다.※ 내부 단계에서 외부 단계로 갈수록 추상화 정도는 높아진다. 1. 외부 단계(각 사용자의 뷰) • 데이터베이스의 각 사용자가 갖는 뷰. 각 사용자가 어떻게 데이터를 보는가를 기술한다. • 대학교 데이터베이스에서 한 학과의 학과장은 학과의 예산과 학생들의 수강 정보..

관계 데이터 모델
■ 관계 데이터 모델• E.F. Codd가 1970년에 관계 데이터 모델을 제안• 실세계의 동일한 구조(릴레이션)의 관점에서 모든 데이터를 논리적으로 구성하며 선언적인 질의어를 통한 데이터 접근을 제공한다. 응용 프로그램들은 데이터베이스 내의 레코드들의 어떠한 순서와도 무관하게 작성된다.• 사용자는 원하는 데이터(what)만 명시하고, 어떻게 이 데이터를 어떻게 찾을 것인가(how)는 명시할 필요가 없다.• 관계 데이터 모델은 논리적으로 연관된 데이터를 연결하기 위해서 링크나 포인터를 사용하지 않는다. 관계 데이터베이스 모델에서는 실세계에서 서로 다른 객체들을 연관시키는 것이 값들의 비교에 의해 이루어진다. 1. 관계 데이터 모델의 목적• 데이터베이스의 관리의 논리적인 면과 물리적인 면을 명확하게 구분하..
DBMS의 언어
• 데이터베이스를 구축하기 위해서 사용자는 먼저 데이터베이스 스키마를 정의한 후에 DBMS에서 제공하는 연산자들을 사용하여 데이터를 저장, 검색, 수정, 삭제하게 된다. 일반적으로 DBMS는 이와 같은 작업을 용이하게 하는 언어들을 제공한다. 1. 데이터 정의어(DDL: Data Definition Language) • 사용자는 데이터 정의어를 사용하여 데이터베이스 스키마를 정의한다. • 데이터 정의어로 명시된 문장이 입력되면 DBMS는 사용자가 정의한 스키마에 대한 명세를 시스템 카탈로그에 저장한다. ※ 시스템 카탈로그는 메타데이터-데이터베이스에 저장된 데이터에 관한 데이터-를 저장한다. • 데이터 구조를 생성(SQL에서 CREATE TABLE) • 데이터 구조를 변경(SQL에서 ALTER TABLE)..

DBMS의 발전 과정
• 60년대와 70년대: 계층 및 네트워크 DBMS(현재는 거의 쓰지 않음)• 80년대 초반: 관계 DBMS• 80년대 후반: 객체 지향 DBMS(OODBMS) = 객체 지향 프로그래밍 + 네트워크 DBMS• 90년대 후반: 객체 관계 DBMS(ORDBMS) = 객체 지향 DBMS + 관계 DBMS 1. 계층 DBMS • 트리 구조를 기반으로 하는 계층 데이터 모델 ※데이터 모델은 데이터베이스 구조를 기술하는데 사용되는 개념들의 집합을 뜻함. -> 구조(데이터 타입과 관계), 이 구조 위에서 동작하는 연산자들, 무결성 제약조건들로 이루어진다. -> 각 데이터 모델은 공통적인 목적을 가지고 있는데, 사용자들에게 내부 저장 방식의 세세한 사항은 숨기면서 데이터에 대한 직관적인 뷰를 제공하는 동시에 이들 간의..
데이터베이스란?
1. 데이터베이스(DB): 데이터는 컴퓨터 디스크와 같은 매체에 저장된 사실을 말한다. 반면 정보는 데이터를 처리해서 사람이 이해하기에 적합한 형태로 의미 있게 만든 것이다. 바로 데이터와 정보의 갭을 줄이기 위해서 데이터베이스가 탄생되었는데, 데이터는 프로그램과 질의에 의해서 정보로 변환된다. 2. 데이터베이스 시스템(DBS): 자료를 데이터베이스에 저장 관리하며 필요한 정보를 제공하는 컴퓨터 기반 시스템. 구성요소는 데이터베이스, 사용자(응용 프로그램), DBMS, 하드웨어로 구성(1) 데이터베이스: 조직체의 응용 시스템들이 공유해서 사용하는 운영 데이터들이 구조적으로 통합된 모임(데이터 구조는 데이터 모델에 의해 결정된다.) (2) DBMS(Database Management System): ① 새..
[C++]포인터와 배열3
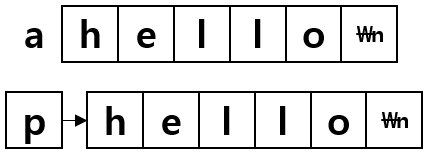
• 포인터와 배열에 대한 마지막 글이 될 것 같다.• 이번 포스트에서는 필자가 포인터와 배열의 공부하면서 가장 헷갈리고 애매했던 것에 대해 이야기하려고 한다.[char a[]와 char *a 차이]• 결론부터 말씀드리자면, char a[]와 char *a는 전혀 다르다.• 차이점은 - 배열: 같은 타입의 연속적인 요소들이 미리 할당된 공간, 크기와 위치가 고정되어 있다. - 포인터: 할당된 메모리 공간을 가리킬 수 있으며, 변경할 수도 있다. 또한 배열을 가리킬 수 있으며, 동적으로 할당한 배열처럼 흉내내어 쓸 수 있다. • 아마 헷갈리는 이유는 함수의 Formal Parameter에 관한 것이라 생각한다.(cf. void func(char * a); 라는 함수를 호출할 때 char a[]; func(a..
[C++]포인터와 배열2
[포인터 배열] • 배열을 가리키는 포인터를 뜻한다. 그럼 초기화 방법을 보도록 하자. #include using namespace std; int main(void) { int arr[3]; int *p; p = arr; // 배열의 이름은 배열의 시작주소를 나타내는 상수 값 cout ※ int a[2][3][4] - int형 배열 메모리(int [3][4])가 2개 있는 3차원 배열을 뜻함 - 각 요소가 int[3][4]형 이므로 int [3][4]를 가리키는 포인터(int (*p)[3][4])를 선언한다. [예시 2] #include using namespace std; int main(void) { int a[2][3] = { 1, 2, 3, 4, 5, 6 }; int(*p)[3] = a; for..

[C++]포인터와 배열1
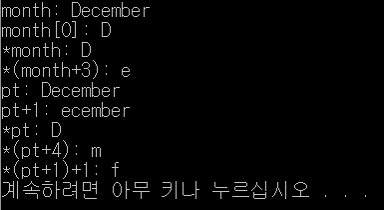
• 필자는 크게 포인터와 배열의 관계에서 크게 “포인터 배열”과 “배열 포인터”가 있다고 생각한다.• 참고로 필자는 “포인터 배열”과 “배열 포인터”에 대해 용어가 혼동이 왔었는데 아래와 같이 화살표를 그려서 혼동을 해결했다. 필요한 사람만 참고했으면 좋겠다. - 포인터 배열 : 포인터→배열 – 포인터는 배열을 가리킴! - 배열 포인터 : 배열→포인터 – 배열은 포인터다! [포인터와 배열 사이의 기본적인 관계 이해] • 우선 배열의 이름이 갖는 의미부터 명확하게 집고 넘어가야 한다.• n차원 배열의 이름은 배열의 선두번지 주소를 대표한다.• 배열의 이름은 상수인 것이다!• 아래 예시는 기본적인 것이니 답을 보지 말고 출력을 예상해보자. #include using namespace std; int main..
[C++]포인터
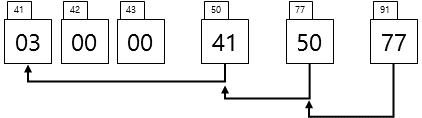
[포인터 개념] • 변수의 주소나 배열의 이름을 포인터의 값으로 가진다. • 주 메모리상의 여러 형태의 주소를 값으로 취한다. • 포인터가 1byte char형을 가리키던 8byte double형을 가리키던 가리켜야 할 주소는 모두 4byte(32bit)이다. [주소 개념 이해] • 변수 앞에 &를 붙일 경우 변수의 주소를 말한다. • ‘&’를 주소 연산자라고 한다. • 주소는 컴파일러에 의해 결정된다. [포인터 초기화 방법] //방법 1 int a = 26; int *pa; pa = &a; //방법 2 int b = 26; int *pb = &b; [예시1] int a = 7; int *p = &a a 표현출력 값설명p 표현a7a 변수의 값*p==*(0x789)&a0x789a 변수의 주소p*&a7a 변..